

What is Data Consistency? Definition, Examples, and Best Practices


If you care about whether your business succeeds or fails, you should care about data consistency. Consistent data is important because it has a huge impact on your bottom line. Unfortunately, that impact often goes undetected—until it’s too late.
Say your business uses data for operational purposes, and your data is inconsistent, leading to low data integrity. You could inadvertently send an automated renewal email to a customer who’s at risk of churning because your “account status” wasn’t identical across Gainsight and Salesforce, leading to lack of concurrency.
If your business uses data for decision-making purposes, on the other hand, and your data is inconsistent, it could cost you. As an example, imagine deciding to double-down on digital advertising because your return on ad spend appeared high, when according to a second source you’re barely breaking even.
Now that you know why data consistency matters, let’s dive into exactly what it means. In this blog post, you’ll find a definition, examples, and four methods for measuring data consistency.
What is data consistency?
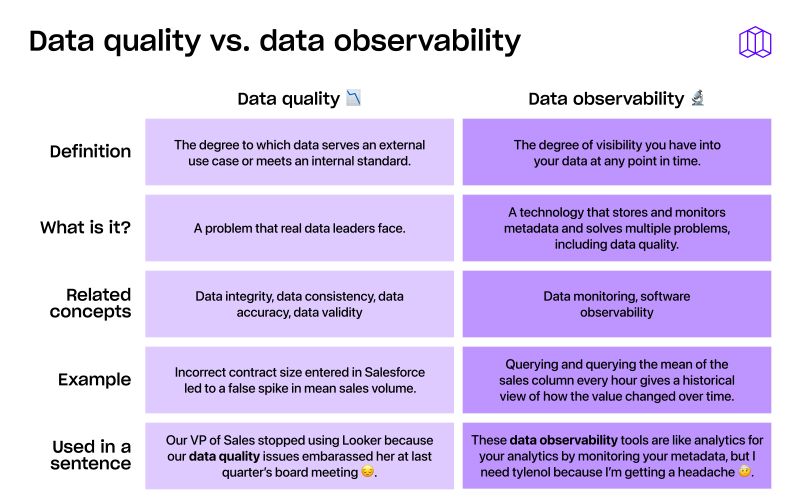
Data consistency is one of ten dimensions of data quality. Data is considered consistent if two or more values in different locations are identical. Ask yourself: Is the data internally consistent? If there are redundant data values, do they have the same value? Or, if values are aggregations of each other, are the values consistent with each other?
What are some examples of inconsistent data?
Imagine you’re a lead analytics engineer at Rainforest, an ecommerce company that sells hydroponic aquariums to high-end restaurants. An example of data inconsistency here would be if the engineering team records aquarium models from database transactions that don’t match the models recorded by the sales team from the CRM.

Another example would be if the monthly profit number is not consistent with the monthly revenue and cost numbers. Some of the ways that this could happen would be if you have concurrent workloads, which could be in the form replication pipelines themselves, or downstream SQL transformations that lead to additional nodes (forks) in your end to end pipelines. The solution to all of this would be proper data management, starting with measuring for data consistency.
{{inline-a}}
How do you measure data consistency?
To test your any data quality dimension, you must measure, track, and assess a relevant data quality metric. In the case of data consistency, you can measure the number of passed checks to track the uniqueness of values, uniqueness of entities, corroboration within the system, or whether referential integrity is maintained. Codd’s Referential Integrity constraint is one example of a consistency check.
{{inline-a}}
How to ensure data consistency
One way to ensure data consistency is through anomaly detection, sometimes called outlier analysis, which helps you to identify unexpected values or events in a data set.
Using the example of two numbers that are inconsistent with one another, anomaly detection software would notify you instantly when data you expect to match doesn’t. The software knows it’s unusual because its machine learning model learns from your historical metadata.
Here’s how anomaly detection helps Andrew Mackenzie, Business Intelligence Architect at Appcues, perform his role:
“The important thing is that when things break, I know immediately—and I can usually fix them before any of my stakeholders find out.”
In other words, you can say goodbye to the dreaded WTF message from your stakeholders. In that way, automated, real-time anomaly detection is like a friend who has always got your back.
FAQ
How does data consistency differ from application consistency vs strong consistency?
For purposes of this article, we've be focused solely on data consistency as it relates to the actual values themselves. You may see some overlap with Strong Consistency and Application Consistency, other terms in the data space:
- Strong Consistency: You may run into this term when looking up database consistency as well, particularly in complex database system architectures. Strong consistency is all about ensuring that everyone in a distributed system is on the same page when it comes to data, and includes the concepts from CAP theorem. It means that no matter which node or replica you're looking at, they all have the most up-to-date view of the data at any given time. It's like making sure everyone sees things happening in the same order, as if there's only one copy of the data. So, when you read something, you can always trust that you're getting the latest version. Achieving strong consistency usually involves using coordination mechanisms like distributed transactions or consensus algorithms to make sure the data stays intact and in sync across the entire distributed system. Note: It’s important here to maintain atomicity of timestamps to ensure you don’t miss any data changes.
- Application Consistency: Application consistency refers to making sure that the data within an application (app), typically hosted in your database system, is in good shape and follows the rules and requirements set by that application. It's like ensuring that everything is in order and makes sense according to how the app is supposed to work. When an app is consistent, you can trust that the data is accurate, complete, and meets the specific rules or relationships defined by the app. It's all about making sure things run smoothly and produce reliable results. To achieve application consistency, developers need to implement checks and safeguards to validate data, handle errors effectively, and enforce the application's unique rules. Note: a crossover here in data governance may be to utilize data validation during a user’s data entry (e.g. email) to ensure that downstream usage of that field can be maintained.
For simplicity’s sake, when we’re referring to data consistency here, the concepts will be largely applicable to your data warehouse of choice.
To take anomaly detection for a spin and put an end to poor data quality, sign up for Metaplane’s free-forever plan or test our most advanced features with a 14-day free trial. Implementation takes under 30 minutes.
Table of contents
Tags



...



...








.png)

.png)
.png)
.png)
.png)
