

Everything you need to know about dbt tests: How to write them, examples, and best practices
Here's everything you need to know about dbt tests, including what they are, how to write them, examples, and best practices for implementing them in your data workflow.


Over 25,000 companies use dbt (data build tool), so it’s safe to say it’s quite popular in the data analytics and engineering scene. In the modern data stack, dbt plays a crucial role in automating data transformations to ensure data quality, and drive transparency in the data workflow.
One of the most important tasks data engineers handle is ensuring data quality and integrity across the data pipeline. This is done by running dbt tests, which identify data anomalies and issues early in the data transformation process.
With dbt, analytics engineers are able to automate testing which reduces errors, builds trust in analytics, avoids data downtime and supports a culture of data-driven decision-making. However, navigating dbt tests can be a bit confusing especially when trying to understand the nuances of dbt tests. You might be wondering how to set up your first test or how to run tests in your CI/CD pipeline, this guide includes everything you need to know about dbt tests.
Let’s dive in.
What are dbt tests?
A dbt test is an assertion to validate data models to ensure data quality and integrity. While tests are commonly associated with validating models, they can also be applied to other dbt objects such as sources, seeds, and snapshots.
Tests are primarily used to confirm that the data meets expectations. This includes checking for null values, ensuring values fall within a defined range, or verifying relationships between datasets. Additionally, dbt allows for the creation of custom tests to validate specific business logic or rules unique to the data pipeline.
Types of tests in dbt
There are two main types of dbt tests: generic and custom. Generic tests are pre-built tests in dbt, defined in schema.yml, for common data quality checks. They're easy to implement and require minimal effort. Custom tests are customized tests that you develop to validate specific business logic or project-specific validation rules.
Custom tests require more complex SQL queries to check for specific conditions that go beyond standard data integrity checks. Custom and generic tests serve different but complementary purposes in ensuring data quality, and knowing when and how to use each type allows you to build a more robust and reliable data pipeline.
Built-in generic tests
Generic tests are also referred to as schema tests which are predefined and are predefined in dbt. The most common generic tests include:
- Unique
- Not Null
- Accepted values
- Relationships
Unique tests
Unique tests verify that every value in a specified column is distinct and ensures that there are no duplicates. These tests are particularly important for columns meant to serve as unique identifiers, such as `order_id`, `customer_id`. Unique tests maintain data integrity and prevent errors caused by duplicate entries.
For example, a unique test applied to the `order_id` column might look like this:
```sql
columns:
- name: order_id
tests:
- unique
```
Not null
Not null tests ensure that no `NULL` values exist in a column. These tests are commonly used in mandatory fields like `order_date` or `customer_email`, to ensure there is no missing information which could disrupt data analytics.
A not null test applied to the `order_date` column might look like this:
```sql
columns:
- name: order_date
tests:
- not_null
```
Accepted values
Accepted values tests verify that a column’s entries match a specific, predefined set of valid options. The valid options are based on the business logic or rules governing the data. Accepted value tests are useful for fields with limited, controlled values, such as `status` or `region_code`, to ensure data consistency and prevent invalid entries.
For example, an `accepted_values` test for the status column would be configured as follows:
```sql
columns:
- name: status
tests:
- accepted_values:
values: ['pending', 'completed', 'cancelled']
```
Relationships
Relationships tests validate that foreign key relationships are maintained between two tables. A foreign key is a column in one table that establishes a relationship with the primary key in another table.
For instance, data engineers use a relationship test to validate that every `customer_id` in the `orders` table corresponds to a valid id in the `customers` table. Relationships tests validate data integrity.
```sql
columns:
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: id
```
Custom generic tests
Custom generic tests are reusable tests used to define complex or project-specific rules tailored to your data needs. You get to define and create the tests, depending on what you want to validate. For instance, you can validate domain-specific constraints, such as ensuring `sales_amount` contains no negative values, or enforce consistency by reapplying the same logic across multiple models or columns.
How to create custom generic tests
1. Define the test in SQL
Create a custom test by defining it in a .sql file within the macros/ folder. For example, to test for positive values, you can create a file named test_positive_values.sql.
```sql
{% test test_positive_values(model, column_name) %}
SELECT *
FROM {{ model }}
WHERE {{ column_name }} <= 0
{% endtest %}
```
The file is now: `macros/custom_tests/test_positive_values.sql`
2. Reference the test in schema.yml:
Add the custom test to your schema.yml file, specifying the column where it should be applied. For instance, this configuration ensures that dbt will run the `test_positive_values` test on the `sales_amount` column, checking for any non-positive values.
```sql
columns:
- name: sales_amount
tests:
- test_positive_values
```
This test ensures that the custom rules are validated and integrated seamlessly into the dbt project.
Singular tests
Singular tests validate specific logic or assertions that are not tied to a particular column and are defined as standalone SQL queries in the `tests/` folder. These tests are used to enforce rules that apply across models. Singular tests ensure data integrity or enforce business rules.
Additionally, data engineers run singular tests for one-off checks that don’t fit into standard column-based tests. A singular test returns rows that fail the test, highlighting where the data doesn't meet the specified criteria.
Writing singular tests:
- Create a SQL file in the `tests/` folder: The test is written as a standalone SQL query
- Write the SQL query for the test: The query should check a specific logic or rule, such as validating relationships between tables or checking for data anomalies. Data engineers typically use `SELECT` statements with the necessary `JOIN`, `WHERE`, and other SQL logic.
- Reference the relevant models (tables/views): Use the `ref()` function to refer to models (tables or views) in your dbt project. The `ref()` function ensures that dbt handles the dependencies correctly.
- Save the file: Save the SQL file in the `tests/` folder with a descriptive name, such as `test_orders_with_no_customers.sql`.
- Run the test: After creating the test, run it using the following dbt `test` command
Let’s say you want to create a singular test to check if any orders in the `orders` table don’t have an associated customer in the `customers` table.
Here’s what it looks like:
```sql
SELECT o.order_id
FROM {{ ref('orders') }} o
LEFT JOIN {{ ref('customers') }} c
ON o.customer_id = c.customer_id
WHERE c.customer_id IS NULL
```
Unit tests
Unit tests in dbt validate the correctness of complex transformations or logic within models. Similar to traditional software unit tests, these tests work by isolating specific logic for validation. Suppose you have a transformation in your `sales` model where you're calculating the total sales amount for each customer. You want to validate that the `total_sales` field is correctly calculated by summing individual sales values.
Unit tests allow data engineers to create a test model that mimics the actual data but only includes a small subset of data relevant to the calculation. Unit tests isolate specific data transformations or processes, which makes debugging easier as data engineers can quickly identify issues in individual components of the data pipeline. Testing small, focused pieces of logic (such as data cleaning steps, aggregations, or transformations) means that engineers can validate each part of the pipeline before moving on to the next stage.
Here is an example with a small dataset that includes two e-commerce orders. One has a positive order amount, and the other has a negative order amount. The goal is to test the logic that ensures the order amount is never negative.
```sql
SELECT 1 AS order_id, '2024-01-01' AS order_date, 100 AS order_amount
UNION ALL
SELECT 2 AS order_id, '2024-01-02' AS order_date, -50 AS order_amount
```
In this test dataset, we have:
- A valid order with a positive amount (100).
- An invalid order with a negative amount (-50).
Next, we write an assertion using `tests/` to create a singular test to validate the logic of ensuring that the `order_amount` should never be negative. This is done by creating a file in the `tests/` folder, such as `tests/test_positive_order_amount.sql`:
```sql
SELECT *
FROM {{ ref('test_orders') }}
WHERE order_amount <0
```
This test query checks if there are any orders in the test_orders table with a negative order_amount. Since the test dataset includes an invalid negative value, this query will return that row.
Next, run the following test command to execute the test:
```sql
dbt test
```
The `test` command validates the results, ensuring that no rows are returned to confirm the logic is working as intended. If the test returns rows where the `order_amount` is negative, it indicates an error in the data. This allows you to isolate the failure and address the specific logic causing the issue.
Here’s a quick recap of dbt tests:
How dbt tests fit into CI/CD pipelines
When integrated with CI/CD pipelines, dbt can provide a solid framework for testing, deploying, and monitoring data models, ensuring data reliability at every step. Validating code before it reaches production enables engineers to avoid spending time addressing issues from broken reports and maintains trust in data systems.
A well-configured CI/CD setup can minimize downtime and prevent unnecessary disruptions. For example, you can automate the testing and validation of your data transformations by triggering a CI/CD pipeline whenever code changes are made, ensuring your models are reliable and ready for deployment.
Metaplane customers like Gorgias use Metaplane’s CI/CD tool to automate testing. With over 20 data analysts and engineers developing models in dbt, the data analytics and engineering team ensure that they’re able to identify affected models and prevent code changes from impacting the data.
Even in organizations with a strong data culture that emphasizes testing code before merging into the main branch, engineers may occasionally skip testing (intentionally or unintentionally).
When a model is edited and merged into the main branch without testing, downstream models may fail to build in the production environment. Or, a critical table like the `customers` table breaks, leaving other teams that rely on data frustrated with outdated or missing data.
Additionally, changes to SQL logic may sometimes be made without approval for new business rules or the logic is incorrect, which leads to errors. While extending code reviews or increasing the number of approvers might address these issues, data engineers need an automated process to maintain reliability and efficiency.
More specifically, here’s more about dbt’s role in CI/CD pipelines:
Automated testing with dbt
dbt's testing framework provides the foundation for CI/CD in data pipelines. Automated built in or custom dbt tests take place directly into the CI/CD pipeline when engineers make changes to data models. Automated testing in the CI/CD pipeline ensures that any issues with data quality, such as broken pipelines or failed transformations, are detected early on and prevent broken pipelines from progressing.
Data and analytics engineer, Elliot Trabac from Gorgias notes “having additional information, like being aware of what changes will happen and which models they’ll affect, alongside existing CI/CD checks, adds an extra layer of security.” Automated testing with dbt streamlines the workflow and also enhances the reliability and accuracy of data transformations.
Code and model validation
dbt plays a key role in validating code and models before deployment to ensure smooth and reliable data transformations. Syntax validation ensures that SQL code and dbt configuration files, like schema.yml and dbt_project.yml, are written correctly and there are no errors.
Model builds validate that the data models are compiled correctly and function as expected when tested with sample or live data. These automated checks within a CI/CD pipeline flag potential issues early, which streamlines the deployment process and enhances the reliability of data models before they reach production.
Lineage and dependency management
dbt data lineage and dependency management automatically generate dependency graphs to track the relationships between models in the data pipeline. During CI, dbt ensures that changes to one model do not break downstream dependencies, while also helping identify which models may be impacted by changes made upstream.
This added visibility allows teams to maintain data integrity and ensures that transformations remain consistent and reliable even as updates are made, while also reducing manual effort in checking how code changes might affect other parts of the pipeline and helping teams avoid errors.
Documentation as a deliverable
With dbt, documentation is automatically updated as part of the CI/CD pipeline, ensuring tha accurate and up-to-date data documentation is available post-deployment. The automated documentation generation helps maintain a consistent record of data models, their dependencies, and transformations, making it easier for teams to understand and collaborate on data projects.
Specifically, this dbt feature supports efficient data governance, promotes transparency, and ensures that everyone in the team is working with the most current and accurate information, as the project evolves.
Environment-specific deployments
dbt allows models to be executed across different environments, such as development, staging, and production, while ensuring a controlled and efficient deployment process. CI/CD pipelines can be configured to first build and test models in staging environments, verifying that everything works as expected without impacting live data.
Once these tests pass, models are safely deployed to production environments, reducing the risk of introducing errors into the live data. This approach provides a structured way to validate data transformations and ensures that only fully tested models make it into production, maintaining the integrity and reliability of the data pipeline.
How to implement dbt tests
We've covered what dbt does, the different types of dbt tests, and why it's important for CI/CD. Now, let's get more tactical and learn how to write and implement dbt tests.
Writing basic built-in tests
dbt provides built-in tests for common data quality checks, which are defined in schema.yml files.
Step 1: Define a Model
Create a model, for example, `models/orders.sql`:
```sql
SELECT * FROM raw.shopify_orders
```
Step 2: Add tests in schema.yml
Define the schema file in the same folder as the model:
```sql
models:
- name: orders
description: "Order data from Shopify"
columns:
- name: order_id
description: "Unique identifier for each order"
tests:
- unique
- not_null
- name: customer_id
description: "Identifier for customers"
tests:
- not_null
```
- `unique` ensures no duplicate values in the column.
- `not_null` ensures there are no `NULL` values.
Step 3: Run the tests
Execute the following command to run the tests:
```sql
dbt test
```
This command will check the `unique` and `not_null` constraints on the specified columns and will fail the test if any issues are detected.
Setting up custom tests
For more complex data validation, you can write custom tests using SQL and YAML.
Step 1: Create a custom test
Custom tests are SQL queries that return rows failing the test.
Create a new test in the `tests` folder, e.g., `tests/test_positive_order_amount.sql`:
```sql
SELECT
*FROM {{ ref('orders') }}
WHERE order_amount <=0
```
Any rows returned by this query indicate a test failure.
Step 2: Register the test in schema.yml
Add the custom test to your schema file:
```sql
models:
- name: orders
description: "Order data from Shopify"
columns:
- name: order_amount
description: "The total amount for the order"
tests:
- not_null
- custom_test: test_positive_order_amount
```
Step 3: Run the custom test
Run the tests, including custom ones:
```sql
dbt test
```
Structuring your tests/ folder for scalability
Organize your `tests/` folder for maintainability and scalability, here is a recommended structure:
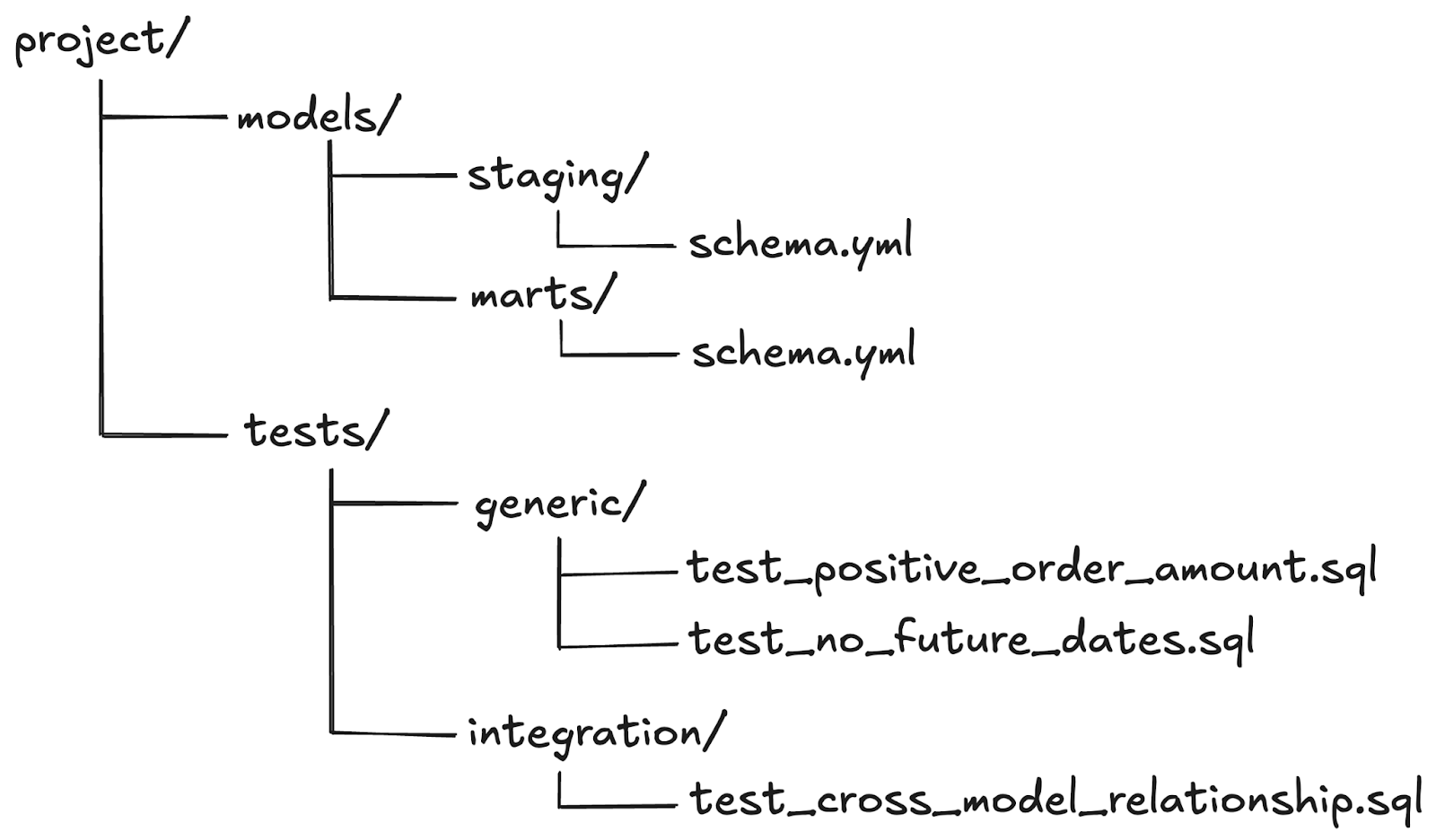
Folder details:
- generic/:
some text- Contains reusable custom tests (e.g., positive values, valid email format).
- These tests can be applied to multiple models or columns via schema.yml.
- integration/:
Contains tests for inter-model relationships (e.g., referential integrity between `orders` and `customers`). - Model-specific tests:
- Simple tests like `unique` or `not_null` are defined in schema.yml near the corresponding model.
Best practices for writing effective dbt tests
Writing dbt tests in one thing, but setting yourself up for success with your testing workflow is another thing entirely. Here's a few best practices to follow when implementing dbt tests.
Use descriptive naming conventions for tests
Choose names that immediately convey the test's purpose to anyone reviewing it. Include relevant details, such as the model being tested and the specific check being performed to provide context. Descriptive names help you quickly identify what a test is checking during debugging or reviewing logs.
Examples of descriptive test names:
- Built-in tests: `unique_customer_id`, `not_null_order_date`
- Custom tests: `test_positive_sales_amount`, `test_valid_email_format`
Create a logical folder structure
Structure your `tests/` folder logically to improve scalability and readability. Organized folders make it easier to locate, maintain, and extend tests.
Recommended structure:
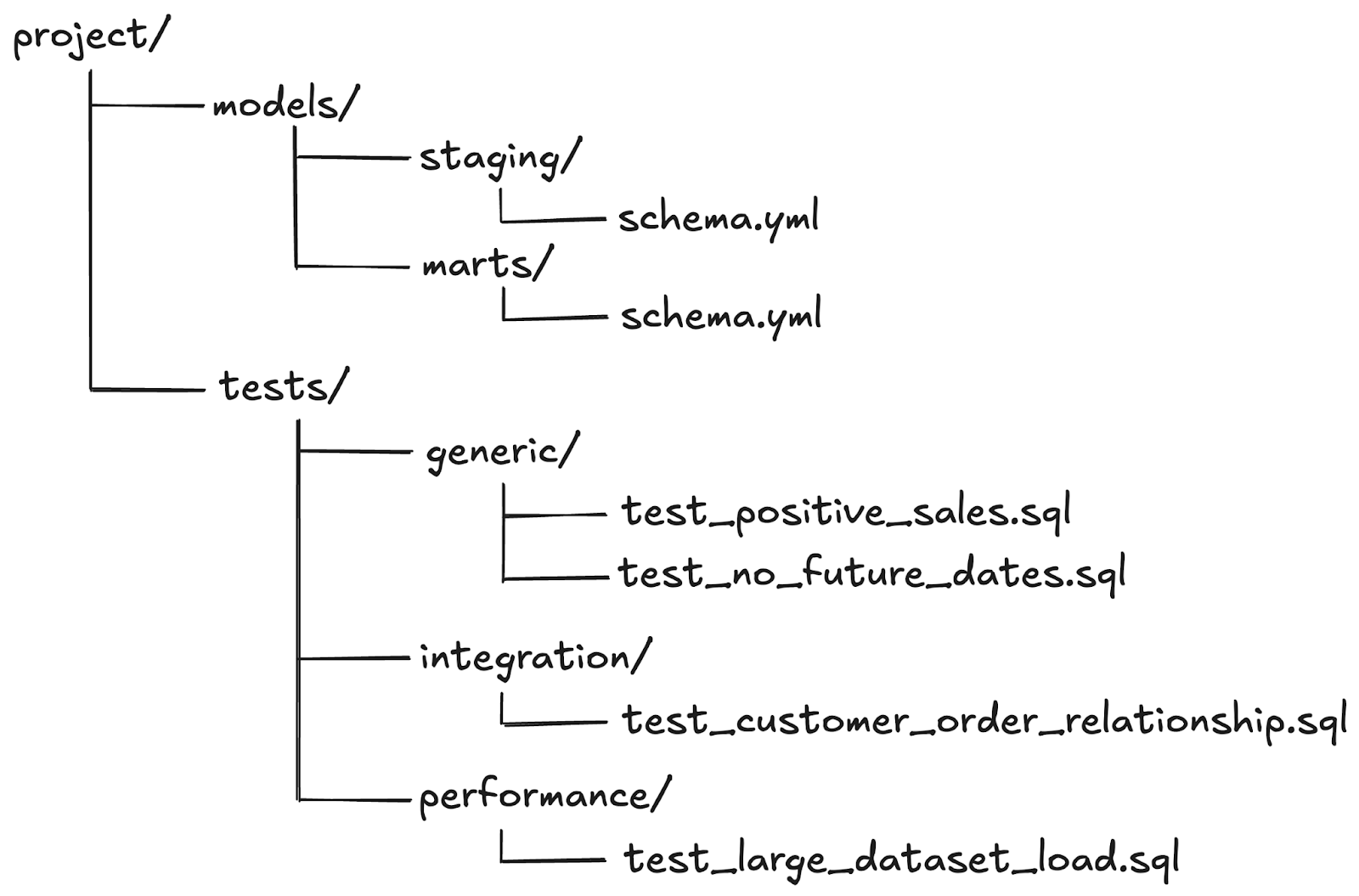
Choose the right granularity for testing
Focus on business-critical rules and avoid redundant testing. For instance, testing uniqueness and null values for the same column separately (which will bring the same results). Apply aggregations thoughtfully, for instance validate total sales over specific date ranges rather than checking every individual row. Under-testing can lead to poor data validation and over-testing can lead to developer inefficiencies.
Use assertions for clear failures
Use SQL assertions to ensure failures are clear and easy to debug. dbt tests should provide actionable results by returning rows that fail a specific condition. Actionable failures help developers quickly locate and fix data issues. For example, in this custom test: `test_no_future_dates.sql`
```sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_date > CURRENT_DATE
```
The SQL assertion is a custom test to ensure there are no future-dated orders in the data. In this test, any rows returned would indicate an issue: orders with a date later than the current date. These actionable failures provide clear, concise feedback that helps developers trace the root cause of the problem and implement fixes efficiently, which maintains data integrity and reliability.
Write tests to ensure clear and actionable failure messages
Clear failure messages reduce debugging time and improves collaboration across teams. For custom tests, provide explicit descriptions for failed rows, this will help other engineers and analysts understand what is wrong. Include context in the assertions in the error messages to make debugging easier.
This test checks the orders table to find rows where order_date is in the future, if any rows are returned, they indicate the specific `order_id` and `order_date` values causing the test to fail. This provides clear, actionable details for debugging.
```sql
SELECT
order_id,
order_date
FROM {{ ref('orders') }}
WHERE order_date > CURRENT_DATE
```
The schema.yml file is where you define metadata, such as test configurations and descriptions for your models and their fields. Use a clear description in your schema.yml.The assertion below includes built-in tests not_null, which ensures there are no NULL values in the order_date column, and relationships, which validates foreign key integrity by confirming that order_date maps correctly to date_sk in the dim_date table.
If these tests fail, dbt generates detailed failure messages, highlighting the rows or conditions that caused the issue, which helps teams address the problem quickly.
```sql
models:
- name: orders
columns:
- name: order_date
tests:
- not_null
- relationships:
to: dim_date
field: date_sk
- custom_test: no_future_dates
```
Track and resolve test failures promptly
Integrate dbt tests with CI/CD pipelines to catch and resolve issues as early as possible. Prompt resolution prevents bad data from propagating to downstream systems. Use dbt artifacts (e.g., run_results.json) to monitor test outcomes. Use Metaplane’s dbt alerting tool to get context-rich alerts to your dashboard for failed tests.
.jpeg)
Metaplane’s dbt alerting tool, enables you to quickly identify test failures with context so you can assess the severity of each failed job faster and manage alert routing across your data team. Avoid alert fatigue by routing the relevant alerts to the right stakeholders.
Combine dbt tests with data observability tools
Execute dbt tests with data observability tools like Metaplane to monitor data quality across your entire data pipeline. While dbt tests validate the correctness of transformations, Metaplane provides automated, granular monitoring that captures nuances specific to data types and sources.
Metaplane accurately captures each step of the data flow and predicts potential data quality issues before they arise. Whenever a new data source is added, an existing source is removed, or a source is renamed, Metaplane automatically detects these changes and incorporates them into the dbt model without any manual intervention. This integration ensures comprehensive, proactive monitoring, allowing for faster identification and resolution of issues, ultimately maintaining data reliability and consistency across your systems.
Run dbt tests for a reliable data pipeline
dbt tests are a crucial tool to ensure data quality and build trust in your data pipeline. Running dbt tests regularly enables you to proactively address issues, avoid downtime, and ensure that your organization’s data is always accurate and reliable.
With Metaplane's end-to-end dbt observability, you can monitor data quality in real-time, track the performance of your dbt models, receive and route alerts for any anomalies or failures to the right stakeholder.
Catch potential issues early and resolve them swiftly to ensure consistent performance, and maintain the integrity of your data-driven decision-making process.
Try Metaplane today to pair your dbt tests with end to end data observability to ensure data quality across your team.
Table of contents
Tags



...




...










